W ostatnim czasie firma OpenAI udostępniła swoim testerom narzędzie graficzne o nazwie DALL-E 2, a niedługo potem inny zespół amerykańskich programistów udostępnił jeszcze szerszej publiczności analogiczne narzędzie o nazwie Midjourney. Obydwa programy są oparte na sztucznej inteligencji (dokładniej na tzw. głębokich sieciach neuronowych) i pozwalają tworzyć obrazy za pomocą opisu tekstowego (tzw. prompt). Poskutkowało to eksplozją pomysłowej, dziwacznej, a czasem pięknej sztuki tworzonej i udostępnianej przez cyfrową społeczność.
Sukcesy obu narzędzi graficznych były na tyle duże, że praktycznie od razu pojawiła się kwestia ich komercjalizacji, choć obydwa ciągle znajdują się w swoich wersjach testowych. Midjourney wybrało model subskrypcyjny pozwalający za opłatą uzyskać ograniczoną lub nieograniczoną możliwość generowania kolejnych obrazów. OpenAI natomiast na obecną chwilę wybrało rozwiązanie polegające na możliwości zakupu tokenów, które mają być wykorzystane do generowania obrazów (choć przy bliższej analizie można uznać to za model subskrypcyjny with extra steps). Szybka komercjalizacja tych projektów jest uzasadniona tym bardziej, że funkcjonowanie sztucznej inteligencji wymaga dość sporej mocy obliczeniowej, a co za tym idzie energii, a także niezbędne jest posiadanie (lub wykupienie) odpowiedniej ilości miejsca, gdzie tak powstałą sztukę można przechowywać.
Komercjalizacja i udostępnienie powyższych narzędzi szerszej publiczności wznowiło toczącą się już od dłuższego czasu debatę na temat – “Kto jest właścicielem stworzonych przez AI obrazów?” Twórcy algorytmu? Użytkownicy? Sam algorytm? W mojej ocenie – obecnie nikt. Zacznijmy jednak od początku.
Bardzo krótka analiza aktualnego stanu prawnego
Na początku była konwencja berneńska. Ta umowa międzynarodowa z 1886 roku cały czas obowiązuje i stanowi rdzeń ochrony prawnoautorskiej utworów w zdecydowanej większości krajów świata. Na jej podstawie poszczególne państwa stworzyły własne systemy ochrony praw autorskich, które jednak – zachowując wspólny rdzeń, są zgodne w kluczowych kwestiach. Jedną z nich jest przyjęcie, że ochronie prawnoautorskiej może podlegać tylko działalność człowieka. Zasada ta łączy dość różne od siebie systemy w USA i Europie. I choć np. brytyjska ustawa o prawie autorskim z 1988 roku stworzyła wyjątek od tej reguły wprowadzając kategorię “compute generated works”, to jak słusznie zauważają komentatorzy – ustawodawca 30 lat temu chciał przyznać raczej ochronę utworom, w których proces tworzenia nadal był znacząco i twórczo zaangażowany człowiek, a nie autonomiczny algorytm.
Odnosząc się natomiast do podejścia organów i judykatury właściwej dla siedziby twórców wspomnianych algorytmów, czyli USA, warto wskazać jako przykład ocenę Komisji Rewizyjnej US Copyright Office z dnia 14 lutego 2022 roku. Utrzymała ona w mocy wcześniejszą decyzję odmawiającą zarejestrowania obrazu stworzonego przez sztuczną inteligencję. Organ ten wskazał jako podstawę swojego stanowiska, brak spełnienia warunku w postaci właśnie autorstwa człowieka. Wnioskodawca argumentował, że skoro prawo przewiduje możliwość posiadania praw autorskich przez spółki, to powinno również umożliwić ich posiadanie przez sztuczną inteligencję. W odpowiedzi na ten argument urząd wskazał, że ani prawo, ani doktryna orzecznicza nie przyznają sztucznej inteligencji zdolności do czynności prawnych, wobec czego AI nie może być stroną umowy.
Oznacza to, że zarówno twórca oprogramowania, jak i sam algorytm nie mogą być właścicielami powstałych obrazów (dalej także: “wytworów” – by odróżnić je od “utworów”)
Co zatem z użytkownikami? To jest z pewnością kwestia mniej oczywista. Użytkownik dostarcza bowiem algorytmowi opis (wspomniany prompt), algorytm go przetwarza i tworzy na jego podstawie (za każdym razem trochę inny) efekt. Używa zatem algorytmu jak narzędzia, z dość jednak ograniczonym wkładem własnym (przypomnijmy też, że pomysły nie są chronione przez prawo autorskie). Użytkownik może natomiast kontynuować pracę nad tak powstałym wytworem, tworząc kolejne iteracje i rozwijając treść opisu tak, aby uzyskać zadowalający efekt.
Wyrażenie “zadowalający” jest tu o tyle ważne, że użytkownik nigdy nie ma pewności co do ostatecznego efektu działań algorytmu, choć może starać się je ukierunkowywać. Stopień udziału użytkownika w powstawaniu wytworów AI jest kluczowy właśnie z tego powodu, że dla przesądzenia czy dany wytwór będzie utworem w rozumienia prawa autorskiego, kluczowe znaczenie będzie miało stwierdzenie, czy to człowiek świadomie przesądził o nadaniu konkretnemu obrazowi określonych właściwości. Tu dochodzimy do momentu, gdy należy rozstrzygnąć, czy opisywane narzędzia pozwalają na spełnienie minimalnego wymogu co do udziału człowieka w tworzeniu utworu. Najprostszą i najbezpieczniejszą odpowiedzią byłoby zapewne prawnicze “to zależy”, jednak nie wniosłoby to za wiele do naszych rozważań.
Moja ocena jest następująca: “Używając Midjourney i DALL-2 i wpisując prompt, użytkownik nie tworzy utworu w rozumieniu przepisów prawa autorskiego”. Nie wnosi on bowiem dostatecznego wkładu twórczego. A efekt, który powstaje jest w pewnym stopniu loterią, na którą użytkownik nie ma wpływu. Tym niemniej powyższe narzędzia mogą służyć artystom do tworzenia utworów, jeżeli zostanie przez nich wniesiony odpowiedni wkład twórczy. Jaki, to będzie jeszcze długo przedmiotem debaty, jednakże sam wybór iteracji obrazu takim wkładem nie jest.
Przykładem chronionego utworu stworzonego przy pomocy Midjourney może być np. poniższy komiks:
 |
żródło: https://www.reddit.com/r/midjourney/comments/wt0h7b/working_on_my_graphic_novel_using_midjourney/
Co na to prawnicy?
Jak z powyższą sytuacją prawną radzą sobie zatem Midjourney oraz DALL-E/OpenAI?
Zacznijmy od regulaminu tego pierwszego
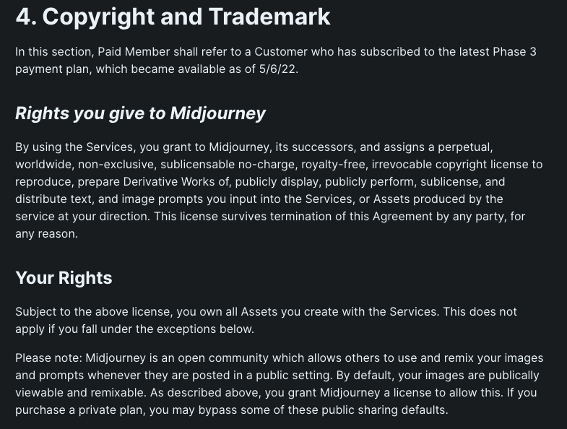 |
https://midjourney.gitbook.io/docs/terms-of-service
Midjourney wyszło wyraźnie z założenia, że efekty pracy ich algorytmu nie powodują powstania po stronie Midjourney utworów objętych ochroną prawnoautorską. Zabezpiecza się natomiast na okoliczność, gdyby takie prawa autorskie powstały po stronie użytkownika. Nie używa też wyrażenia Utwory (Works) w stosunku to stworzonych obrazów, ale Aktywa/zasoby (Asset). Jest to o tyle warte uwagi, że obecnie równolegle toczy się debata właśnie na temat cyfrowych aktywów i ich miejsca w porządku prawnym oraz potencjalnym wykorzystaniu w metaversie.
Wydawałoby się, żę OpenAI podchodzi do tematu podobnie, wskazując użytkownikowi, iż może wykorzystywać w dowolnym celu wygenerowane obrazy a sam nie posiada żadnych praw do niego.
 |
https://openai.com/api/policies/terms/
 |
https://labs.openai.com/policies/terms
W dalszej części regulaminu OpenAI stara się jednak uzyskać nie tyle licencję (jak to robi Midjourney), ale prawo własności do wygenerowanych wytworów, na co użytkownik ma wyrazić zgodę:
 |
https://labs.openai.com/policies/terms
Sformułowanie, że OpenAI jest właścicielem obrazka (choć nie rości sobie do niego praw autorskich) i jednocześnie udziela użytkownikowi pozwolenia na jego reprodukcję i wyświetlanie, połączone z zapewnieniem, że OpenAI nie będzie wysuwać żadnych roszczeń wobec użytkownika, pokazuje, że autorzy tego regulaminu zdawali sobie sprawę z braku “twardych” podstaw do stwierdzenia posiadania przez nich jakichkolwiek praw do wygenerowanych wytworów. Tym niemniej podjęli próbę przynajmniej formalnego zabezpieczenia OpenAI w tej materii. Taka wewnętrznie sprzeczna regulacja nie jest tutaj jednak objawem niekompetencji tworzącej ją prawników, ale raczej pokazuje, jak ciężko czasem w realiach nowych i nowszych technologii uregulować niektóre kwestie.
Co dalej?
Jeżeli zatem uznać, że obecnie obowiązujące przepisy nie przewidują ochrony praw autorskich dla wytworów generowanych przez sztuczną inteligencję, kwestia praw autorskich jest i będzie nadal szeroko dyskutowana, nie tylko w kontekście prawa, ale także w kontekście społeczno-etycznym.
Stanowisko o nieprzyznawaniu praw autorskich do wytworów generowanych maszynowo ma zasadnicze zalety. Nie wymaga zmiany obecnego prawa, wzmacnia zasadę, że to właśnie działalność człowieka podlega ochronie prawnoautorskiej, a szerzej – wymaga istnienia samego autora jako osoby fizycznej. Ostatecznie, pozostawienie obecnego stanu prawnego powinno pomóc zachować miejsce człowieka w obszarze kreatywnym, bowiem tylko jego twórczy udział w stworzeniu danego wytworu przy użyciu sztucznej inteligencji może skutkować powstaniem utworu.
Warto jednak wskazać na powody, dla których stworzenie pewnej formy ochrony takich wytworów może mieć sens. Po pierwsze należy uwzględnić, że pierwowzór systemu ochrony praw autorskich powstał w XIX wieku i nie uwzględnia złożoności obecnej, coraz bardziej cyfrowej rzeczywistości. Nie mniej ważną motywacją do przyznania komuś pewnego rodzaju praw własnościowych jest jednak to, że osoba ta powinna być w jakiś sposób premiowana za umożliwienie komputerowi stworzenia dzieła i następnie jego udostępnienie do wykorzystania przez szerszą publiczność.
Jeśli natomiast prawo uznaje wytwór wygenerowany przez sztuczną inteligencję za niezdolny do bycia przedmiotem praw właścicielskich osoby, która nadała mu kształt i postać – może to ostatecznie prowadzić do świadomych nadużyć. Taka osoba będzie miała bowiem powód, aby poświadczyć nieprawdę co do sposobu powstania danego utworu (przypisując sobie bądź autorstwo w całości bądź jego znacznej, rzekomo twórczej zmiany), w celu uzyskania praw autorskich. Nie bez znaczenia jest też kwestia ekonomiczna – w krótkim czasie liczba wytworów wygenerowanych przez sztuczną inteligencję i nieobjętych żadnym rodzajem praw własnościowych może przewyższyć liczbę utworów stworzonych przez ludzi. Przy takiej ilości nowych, nieustannie powstających wytworów ochrona prawnoautorska może stać się nie tyle trudna, co praktycznie niemożliwa. Obecne systemy ochrony prawnoautorskiej powstały bowiem przy pewnego rodzaju założeniu ograniczonej podaży nowych utworów, uzależnionej od mniejszego lub większego, ale wysiłku i twórczości ludzi. Takie “ludzkie utwory” musiałyby współistnieć z przytłaczającą ilością wytworów sztucznej inteligencji powszechnie i za darmo dostępnych w domenie publicznej. Zmieniłoby się tym samym nastawienie całego społeczeństwa – obecnie bowiem dominującą myślą jest, że dany obraz lub inny utwór może być objęty jakąś formą prawnoautorskiej ochrony – w skrócie może do kogoś należeć. Przy takiej nadprodukcji wytworów, które nie są utworami, szybko przejdziemy do odwrotnej koncepcji, co może ostatecznie przynieść więcej szkody niż pożytku.
Do podobnych wniosków doszedł Parlament Europejski, który w rezolucji z 20 października 2020 roku, wskazuje, iż jest “zdania, że twórczość technologiczna tworzona przez technologie AI musi być chroniona w ramach praw własności intelektualnej, aby zachęcić do inwestowania w tę formę twórczości i zwiększyć pewność prawa dla obywateli, przedsiębiorstw i wynalazców, którzy obecnie należą do najczęstszych użytkowników technologii AI; uważa, że dzieła wyprodukowane samodzielnie przez sztuczne podmioty i roboty mogą nie kwalifikować się do ochrony na podstawie prawa autorskiego w celu poszanowania zasady oryginalności związanej z osobą fizyczną, ponieważ pojęcie „twórczości intelektualnej” odnosi się do osobowości autora”.
Wydaje się zatem, że skoro prawa autorskie mają być przyznane osobie (fizycznej lub prawnej), to ustawodawca będzie musiał podjąć decyzję, czy będzie to programista czy użytkownik. W mojej ocenie powinien być to użytkownik. Warto tu od razu zaznaczyć, że za użytkownika powinno się uznawać tylko osobę mającą legalny dostęp do oprogramowania na licencji/zasadach wskazanych przez jego twórcę (jak we wcześniej analizowanych przypadkach). Prawa autorskie twórcy sztucznej inteligencji są już chronione – ma on pełnię praw do samej sztucznej inteligencji i jeżeli będzie miał taki model biznesowy – sam może stać się jej użytkownikiem, uzyskując w ten sposób stosowną ochronę prawnoautorską. Nawet jeśli użytkownicy nie są ostatecznie w pełni samodzielnymi twórcami wytworów generowanych maszynowo, znajdują się jednak (z ekonomicznego punktu widzenia) w tej samej pozycji co tradycyjni autorzy, ponieważ podejmują pierwsze kroki, które wprowadzają taki utwór na rynek (i doprowadzają do powstania jego ostatecznej formy). Jeżeli zatem założymy, że społeczeństwo ma interes w udostępnianiu tych utworów, najskuteczniejszym rozwiązaniem jest stworzenie zachęt dla użytkowników do ich tworzenia i udostępniania innym.
Pytanie o to, czy taki użytkownik powinien mieć pełnię praw autorskich na dotychczasowych zasadach, czy ustawodawca powinien stworzyć podtyp takich praw lub ich ograniczoną wersję wydaje się już drugorzędne. Choć zapewne ta druga opcja pozwalałaby na utrzymanie większej wartości utworów stworzonych w całości przez człowieka (lub przynajmniej z zachowaniem dotychczasowego wkładu twórczego).
Podsumowanie
Choć obecny stan prawny pozwala na funkcjonowanie wytworów sztucznej inteligencji(można nawet argumentować, że wzmacnia i chroni twórczą działalność człowieka), brak jakiejkolwiek reakcji ustawodawcy na dłuższą metę może okazać się szkodliwy dla artystów.
Przyznanie użytkownikom sztucznej inteligencji chociaż ograniczonej formy ochrony prawnoautorskiej może potencjalnie mieć korzystne skutki w sferze przewidywalności i przestrzegania prawa, innowacji i ludzkiej kreatywności. Może to też pozwolić na rozwój cyber-własności i wzmocnić podmiotowość usługobiorców na rynku cyfrowym.
Biorąc pod uwagę, że obecnie w Unii Europejskiej toczy się bardzo ożywiona dyskusja co do ostatecznego kształtu rozporządzenia mającego uregulować sztuczną inteligencję (i tym samym wzmocnić albo przekreślić jej rozwój na terenie EU), można się spodziewać, że kwestia prawa własności intelektualnej wytworów AI stanie się jednym z głównym punktów w dyskusji. Tymczasem, zachęcając do namysłu, zostawiam Państwa z medytującym kotem.
 |
prompt: meditating cute cat



